Preparing Data for Publication in the Datastore
In order to publish your dataset so the public is able to preview and utilize the data in external web applications, your dataset must be uploaded to the portal’s datastore. The datastore bundles a number of modules and configurations with your CSV files, parses them and saves them into the native database as flat tables. Once properly uploaded to the datastore, your dataset will be available to access via public API.
To upload data to the California Open Data Portal all datasets must be in a flat CSV file format.
Dataset Basics – Create a Machine Readable Dataset
Machine readable is information formatted in a standard computer language that can be read automatically by a web application or computer system such as spreadsheets with header columns that can be exported as comma separated values (CSV).
Converting a non-CSV file to CSV:
Mandatory:
* Create headers for each column (first row/column names) (see Example 1 and 3 below)
* Header values (see Example 1 below)
* Values for fields (see Example 1 below)
Not allowed:
* Merged cells (see Example 3 below)
* Multiple tables (see Example 3 below)
* Notes/descriptions (add this information to your metadata) (see Example 3 below)
* Non-data elements (see Example 3 below)
* Blank row or columns within the data (see Example 1 and 3 below)
* Aggregate (sum of values) rows
Formatting best practices:
* Dates (i.e. years, or actual dates) should be stored as rows (see Example 2 below)
* Each type of numeric field (i.e. percentages or totals) value should be its own row in a single column in numerical format (see Example 1 and 3 below)
* Table should be tall and narrow vs short and wide, 30 columns max is suggested (see Example 2 below)
* IDs and abbreviations should be changed to full names or values
* Columns should be data fields, Rows should be where the values for individual entities are stored (see Example 2 below)
Examples
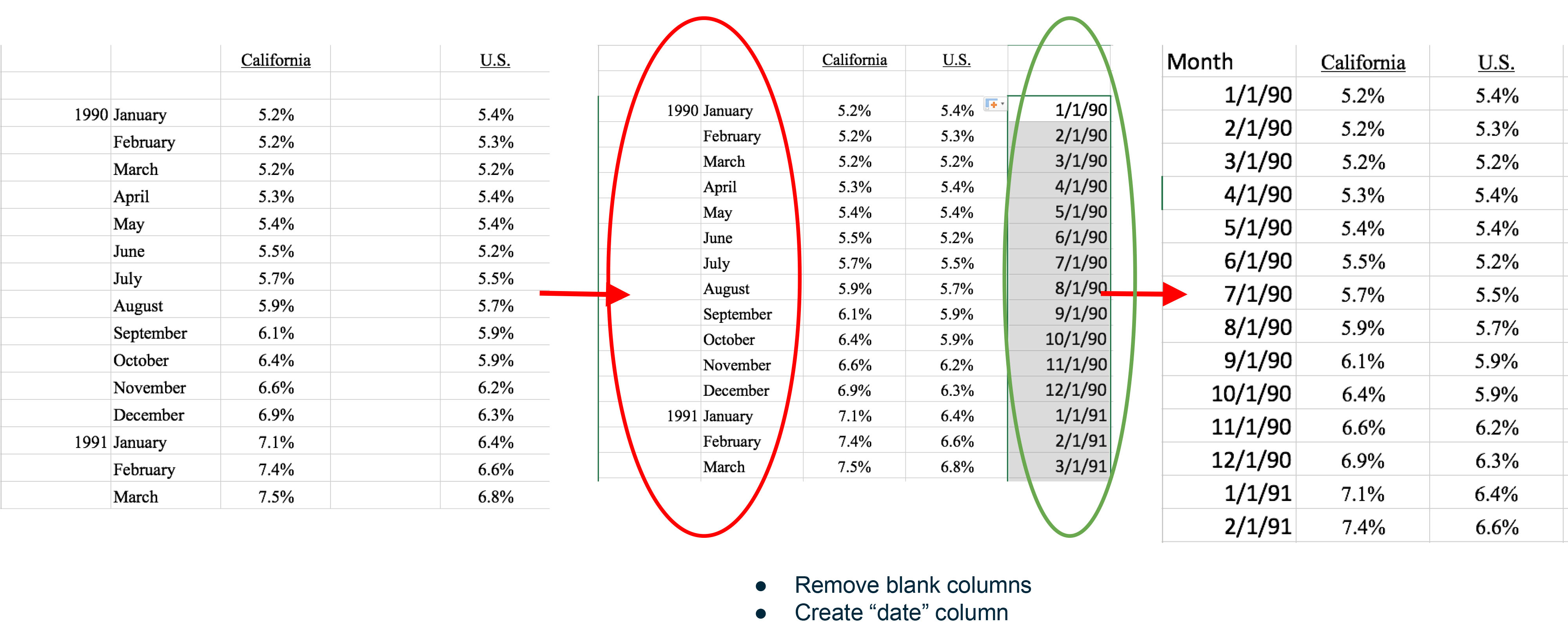
Example 1 demonstrates cleaning up a dataset from improper date format to machine-readable date format by first removing blank cells in columns, then creating a date column, then replacing the old format with the new, single column with a header of 'date' at the top of the column.
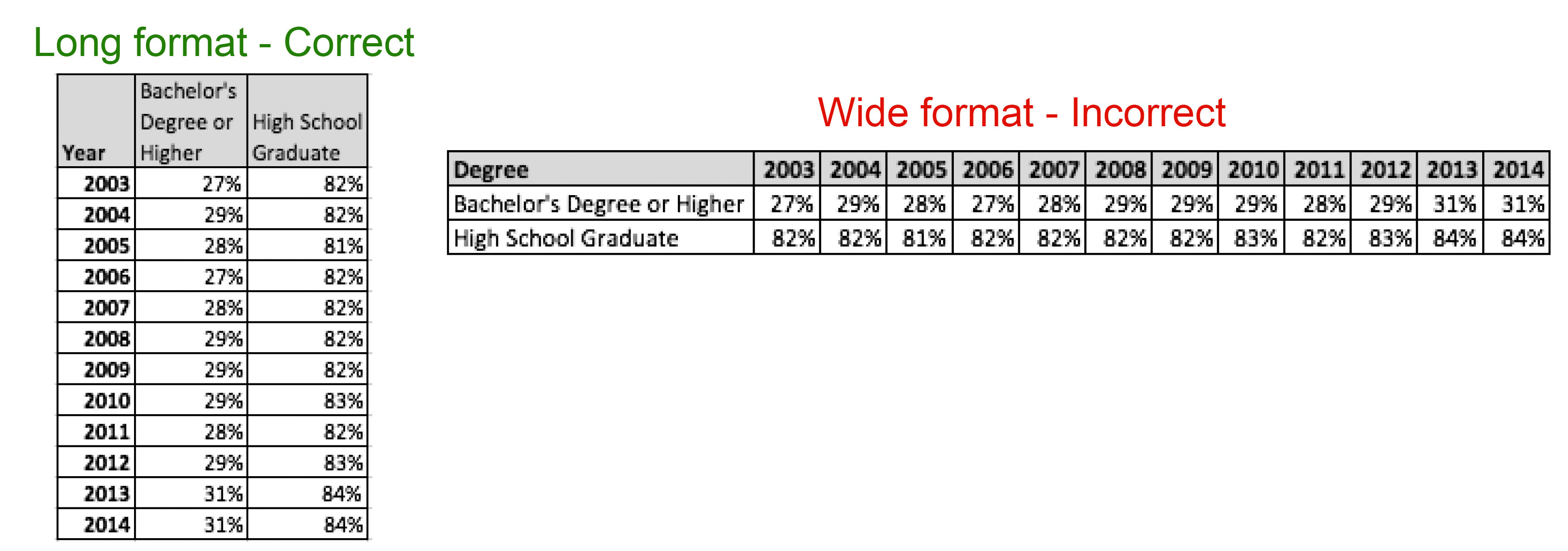
Example 2 is comparing a long formatted dataset to a wide formatted dataset. A long formatted dataset is machine-readable, a wide-formatted dataset is not.
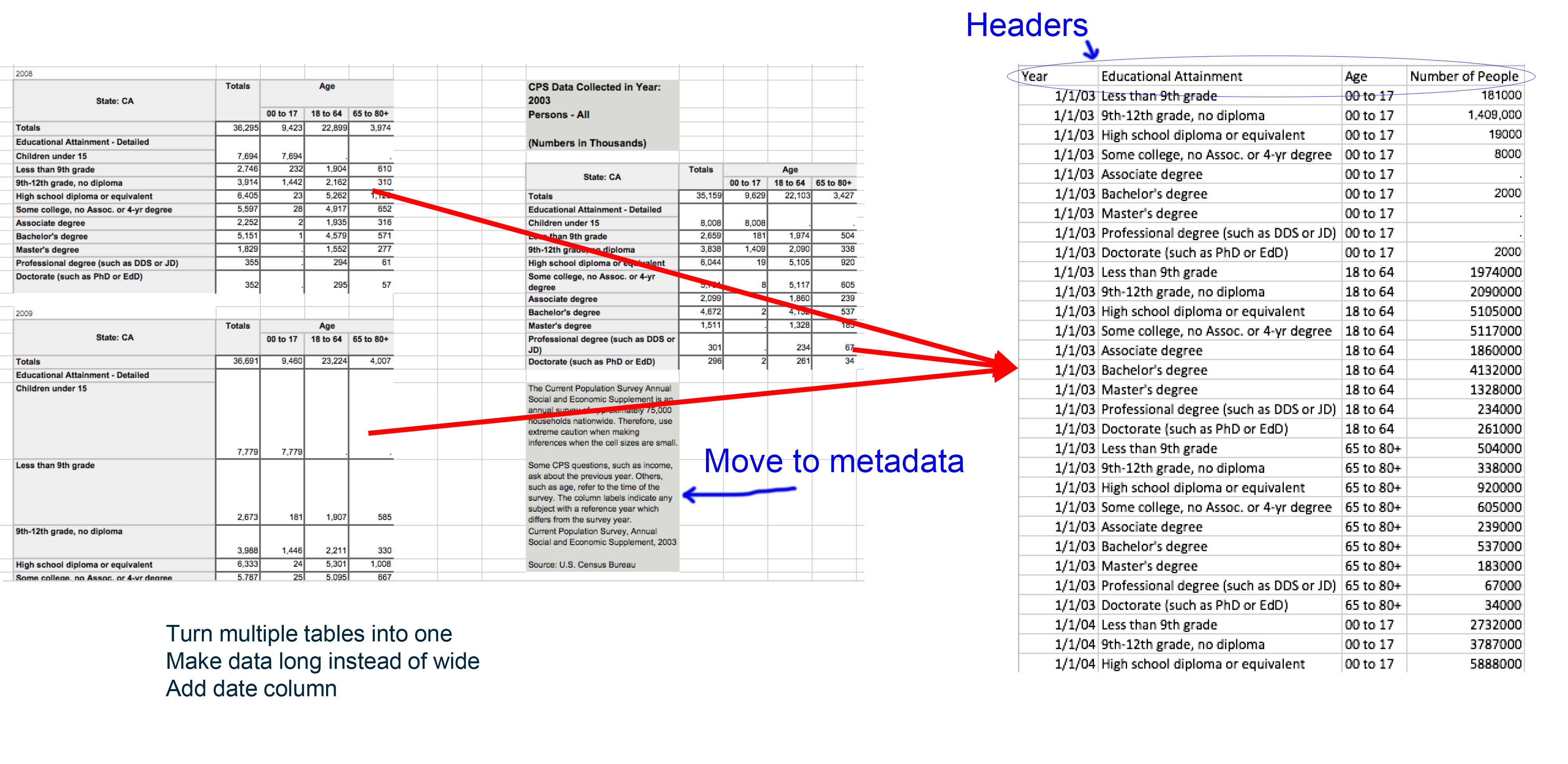
Example 3 shows a multi-table dataset with metadata being converted to a single, machine-readable table. The data has also been converted from wide to long formatting, a date column is created and headers are added to the top of the table. The long description will be moved to a metadata document.
Saving Your Dataset
CSV Basics
Values in flat datasets are separated by delimiters, therefore a “csv” comma separated file is not necessarily separated with commas.
Delimiters
Values in flat datasets are separated by delimiters.
There are five delimiters accepted on the California Open Data Portal:
Comma: ,
Semicolon: ;
Pipe: |
Plus: +
Tabs
Encoding
Computers encode characters (i.e. “a”, “A”, “3”, “$”) in different formats. Any particular character can be encoded in many different ways, depending on which encoding is used to read or write them. For a detailed guide on encoding, click here.
To ensure that people who download your dataset can properly understand the characters when they download it, we require that your file be encoded in UTF-8. This is the standard encoding for most systems and if you are unsure about the encoding of your file, check with the California Department of Technology’s Open Data Team.
What Happens with Your Machine Readable Dataset on Data.ca.gov
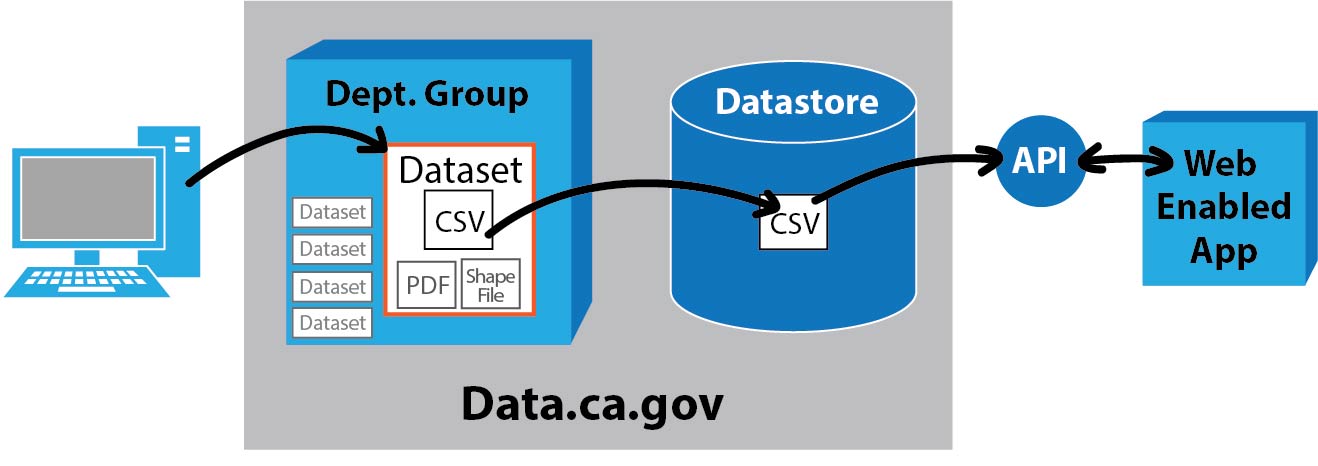
Once your dataset is cleaned up, it can be uploaded to your department's organization on data.ca.gov. Part of your full dataset package is the CSV that you just cleaned up, a data dictionary PDF (learn more about the data dictionary and prepping your metadata here) and could also include additional resources, such as shape files. The metadata is filled out in the upload screen once you are logged into data.ca.gov. Once these files are loaded, your CSV file is automatically pulled into the datastore, which now makes it available for web-enabled applications to access.
Next
The next step is preparing your metadata and data dictionary documents, otherwise go back to the guide contents page.
For more information
Propublica guide to bullet proofing data
What Every Programmer Absolutely, Positively Needs To Know About Encodings and Character Sets to Work with Text